- Published on
A guide to Text-to-SQL
- Authors

- Name
- Arunabh Bora
- @arunabh223
What is a good Text-to-SQL agent?
High-quality text-to-SQL requires more than raw LLM power—it needs domain context, intent disambiguation, and dialect precision. Systems provide LLMs with the necessary business context by retrieving relevant schemas, sampling real data, and adding semantic annotations. Ambiguous queries are clarified through follow-up questions, while SQL-aware models and validation loops ensure accuracy. Continuous evaluation using benchmarks and user feedback drives improvements in accuracy and reliability.
Current challenges
The large language model needs to be complemented with methods to:
- Provide business-specific context
The context can be both explicit (what does the schema look like, what are the relevant columns, and what does the data itself look like?) or more implicit (what is the precise semantic meaning of a piece of data? what does it mean for the specific business case?).
- Understand user intent
An LLM tends to try to give you an answer, and when the question is ambiguous, can be prone to hallucinating.
Example: Take a question like "What are the best-selling shoes?" Here, one obvious point of ambiguity is what "best selling" actually means in the context of the business or application — the most ordered shoes? The shoe brand that brought in the most money? Further, should the SQL count returned orders? And how many kinds of shoes do you want to see in the report? etc.
- Manage differences in SQL dialects
As a simple example, if you're using BigQuery SQL, the correct function for extracting a month from a timestamp column is EXTRACT(MONTH FROM timestamp_column). But if you are using MySQL, you use MONTH(timestamp_column).
A Text-to-SQL system
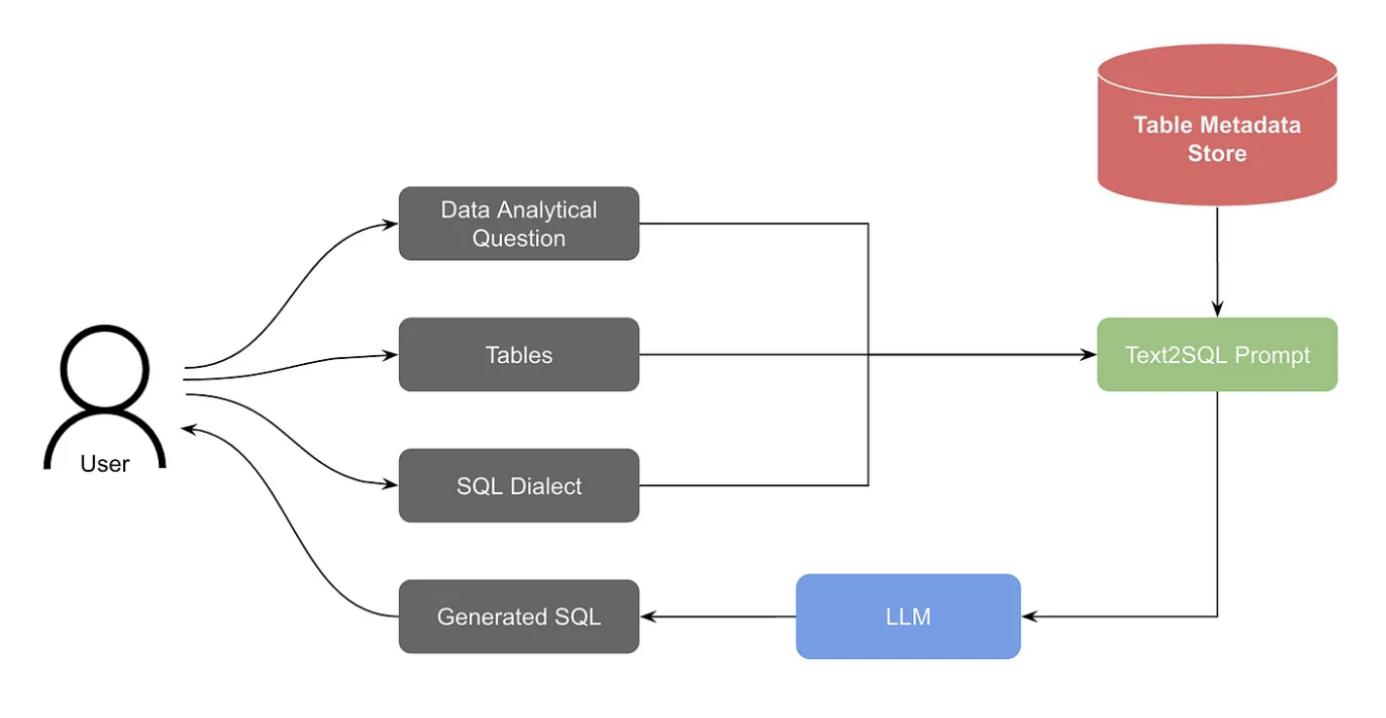
Practices for a good Text-to-SQL system
- Disambugation
Involves getting the system to respond with a clarifying question when faced with a question that is not clear enough (in the example above of "What is the best selling shoe?" should lead to a follow-up question like "Would you like to see the shoes ordered by order quantity or revenue?" from the text-to-SQL agent). Here we typically orchestrate LLM calls to first try to identify if a question can actually be answered given the available schema and data, and if not, to generate the necessary follow-up questions to clarify the user's intent.
- Using SQL aware models
LLMs trained or fine-tuned specifically on SQL tasks tend to produce more accurate and syntactically correct queries. Using models with awareness of SQL structure and logic significantly improves output quality.
- Retrieval and in-context learning (RL)
providing models with the context they need to generate SQL is critical. We use a variety of indexing and retrieval techniques — first to identify relevant datasets, tables and columns, typically using vector search for multi-stage semantic matching, then to load additional useful context. Depending on the product, this may include things like user-provided schema annotations, examples of similar SQL or how to apply specific business rules,
- Validation and reprompting
Even with a high-quality model, there is still some level of non-determinism or unpredictability involved in LLM-driven SQL generation. To address this we have found that non-AI approaches like query parsing or doing a dry run of the generated SQL complements model-based workflows well.