- Published on
Data Lakehouses
- Authors

- Name
- Arunabh Bora
- @arunabh223
What is a Data Lakehouse?
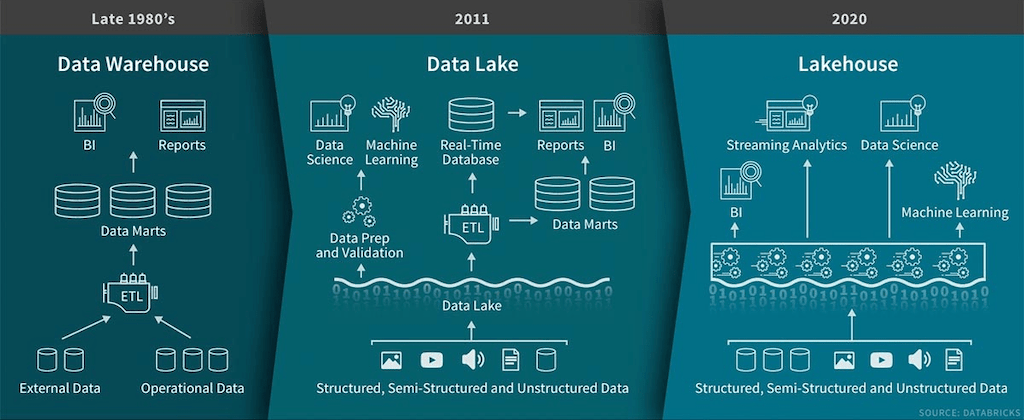
A Data Lakehouse open data management architecture that combines the flexibility, cost-efficiency, and scale of Data Lake with the data management and ACID transactions of Data Warehouse. Lakehouses have Data Lake Table Formats ( Delta Lake, Apache Iceberg & Apache Hudi) that enable Business Intelligence (BI) and Machine Learning (ML) on all data.
What make a data lakehouse so special?
Data lakehouses support open table formats and it has the features of both data lake and a data warehouse. That is, data lakehouses support transactional processing with the storage capabilities of that of a data lake. This is enabled by Delta lake.
Delta lake has many cool features:
- ACID transactions
- Time travel (version history) & Version pruning
- Transaction logs
- SQL API to write native SQL as insert, update, delete and even merge statements
- Apache Parquet open format for data storage
- Schema evolution
- Unified handling of batch and stream data
Open table formats
Data lake file formats are more column-oriented and compress large files with added features. The main players here are Apache Parquet, Apache Avro, and Apache Arrow. These file formats have additional features such as split ability and schema evolution. These are a team and programming language agnostic. Data lake table formats allow you to efficiently query your data directly out of your data lake. No initial transformation is needed. The file formats are good at storing big data in a compressed way and returning it for column-oriented analytical queries.